python爬虫系列-音乐下载
python爬虫网站下载音乐
前言
免责声明:本教程仅供学习和教育使用,不用于任何商业或非法目的。请在使用本教程前确保遵守所有适用的法律法规。对于您使用本教程所产生的任何后果,包括但不限于法律纠纷、知识产权侵权等,本教程不承担任何责任。
准备
需要了解及准备的以下信息:
- python3.8及以上
- requests库
- bs4库
- re库
- json库
- 音乐网站:http://www.2t58.com/
第一步、设置请求标头信息
打开音乐网站
按F12进入开发者选项
点击
Network或者网络,勾选全部然后刷新获取请求随便点击一条请求,点击
标头或者headers复制相关信息,在python中创建一个字典保存请求标头信息,例:
1
2
3
4
5
6headers = {
'Host':'www.2t58.com',
'Referer':'http://www.2t58.com/',
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 Edg/120.0.0.0'
}
第二步、搜索音乐
创建一个url变量存储音乐网站链接
1
url = "http://www.2t58.com/so/"创建一个搜索的方法
def search(url,headers):这个方法实现的功能主要有歌曲下载、歌曲搜索,翻页,以及搜索结果展示。
其中歌曲下载,结果展示可以另外调用其他方法执行。而翻页又可以用搜索结果展示
用data,page_lish接收(调用)搜索结果返回的歌曲信息(歌名:链接),页码信息
用downloda_resu接收下载结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84def search(url, headers):
so = 'so/'
name = str(input("请输入歌名/歌手(输入1122退出):"))
if name == "1122":
return False
s_url = url + so + name + '.html'
response = requests.get(s_url, headers)
soup = BeautifulSoup(response.text, "html.parser")
data, page_list = search_list(soup, None, headers)
# 页码
end_page_url = [item.get('End') for item in page_list if 'End' in item][0] # 尾页的链接
# 这里有一个小坑,search_name是从网页元素中text字符串截取出来的
# 网页中这段文字有空格,所以要用用户输入的name截取页码
end_page_index_start = end_page_url.find(name + '/') + len(name + '/')
end_page_index_end = end_page_url.find('.html')
end_page_num = end_page_url[end_page_index_start:end_page_index_end]
current_page = [item.get('Cur_Pg') for item in page_list if 'Cur_Pg' in item][0]
print(f"第{current_page}/{end_page_num}页\t")
# 指令
while True:
# 翻页
## 页码url获取
pgup = None
pgdw = None
home = None
end = None
for page_item in page_list:
## 赋值翻页url
if 'PgDw' in page_item:
pgdw = page_item['PgDw']
elif 'PgUp' in page_item:
pgup = page_item['PgUp']
elif 'Home' in page_item:
home = page_item['Home']
elif 'End' in page_item:
end = page_item['End']
print("输入歌曲前面的序号下载,输入h跳转到第一页,输入e跳转到最后一页,输入u上一页,输入d下一页")
instructions = input("请输入:")
if instructions == "d" or instructions == "D":
if pgdw is not None:
pgdw_url = url + pgdw
data, page_list = search_list(soup,pgdw_url,headers)
else:
print("当前是最后一页。")
elif instructions == 'u' or instructions == 'U':
if pgup is not None:
pgup_url = url + pgup
data, page_list = search_list(soup, pgup_url, headers)
else:
print("当前是第一页")
elif instructions == 'h' or instructions == 'H':
if home is not None:
home_url = url + home
data, page_list = search_list(soup, home_url, headers)
else:
print("当前是第一页")
elif instructions == 'e' or instructions == 'E':
if end is not None:
end_url = url + end
data, page_list = search_list(soup, end_url, headers)
else:
print("当前是最后一页")
# 下载歌曲
elif instructions.isdigit():
instructions = int(instructions)
if instructions > len(data) or instructions < 1:
print("请输入歌曲前面的序号")
continue
song_url =url + data[instructions - 1]['url']
downloda_resu = song_download(song_url,'music')
if downloda_resu:
continu_inst = input("是否继续下载y/n(任意键退出程序):")
if continu_inst == "y" or continu_inst == "Y":
continue
elif continu_inst == "n" or continu_inst == "N":
return True
else:
return False
else:
return False
第三步、歌曲列表展示及歌曲链接
创建一个
def search_list(soup, url, headers):方法suop是初始搜索歌曲时获取到的html数据,url是翻页链接,当url为空时,是初始搜索时展示的第一页歌曲信息,url不为空,说明得到了翻页指令,要重新解析翻页链接得到html元素在展示新页面的歌曲信息。
其中data数据格式是:
1
[{'name': '陈奕迅 - 爱情转移-《爱情呼叫转移》电影主题曲|《富士山下》国语版', 'url': '/song/bWRza2ht.html'}, {'name': '陈奕迅 - 富士山下-《爱情转移》粤语版', 'url': '/song/ZHdubmRr.html'}]page_lish数据格式是:
1
[{'Cur_Pg': '2'}, {'Home': '/so/富士山下/1.html'}, {'PgUp': '/so/富士山下/1.html'}, {'PgDw': '/so/富士山下/3.html'}, {'End': '/so/富士山下/7.html'}]
代码:
1 | |
第四步、歌曲下载
当做到这一步时,兴致勃勃的以为就要大工告成了。
开心的打开歌曲播放页面,按下万能的
F12,怎么着?找到音乐资源藏在了一个audio的标签里面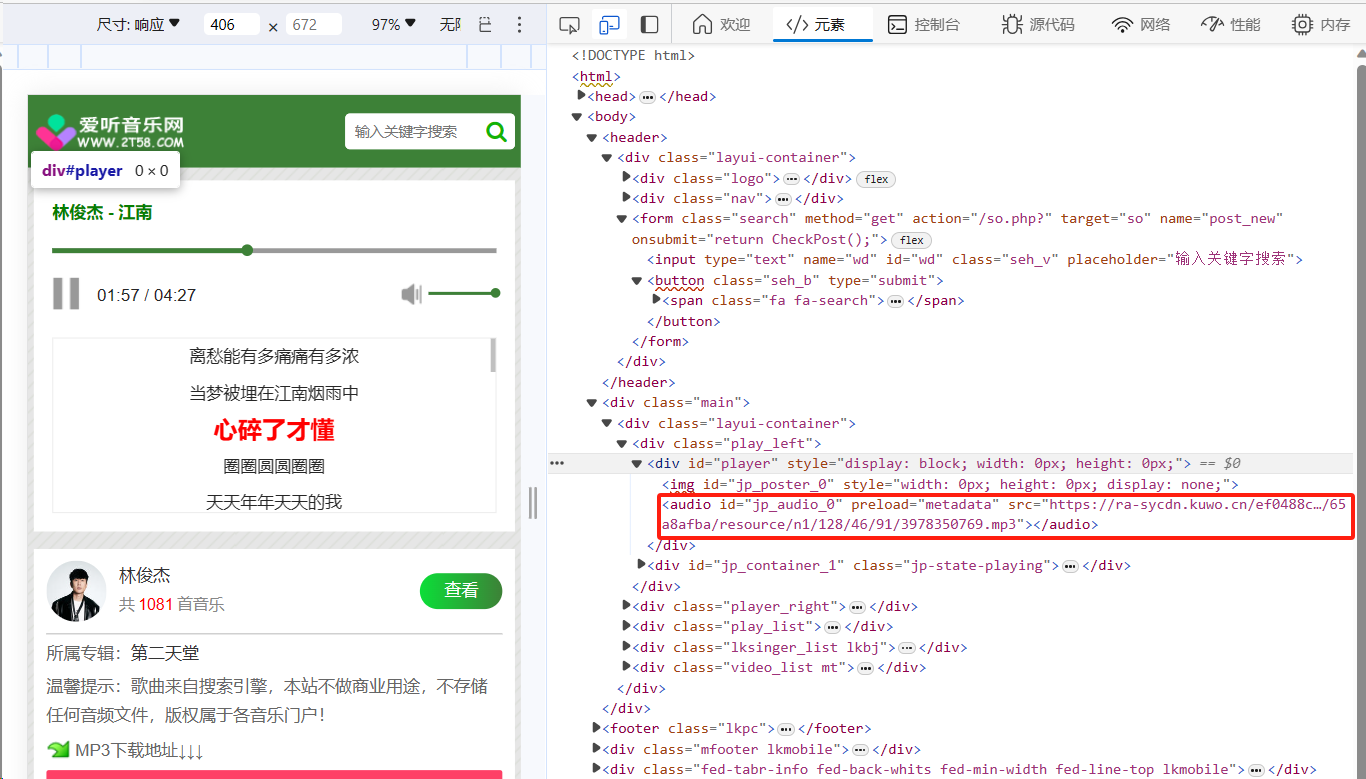
打开python,resquests.get一下这个页面,用bs4处理去找
audio这个标签下的src值,怎么着?它给我报错了,说找不到audio这个标签。把soup打印出来看一下,确实是没有audio这个标签,与网页源代码对比,少了一个播放器player。
猜想:音乐资源和播放器是通过js脚本动态加载的,get获取只能获取静态资源,所以没有audio这个标签。
验证:刷新网页,打开事件侦听器,播放音乐…没反应。查看html元素是否存在
audio,刚打开,就侦听到了两个js脚本。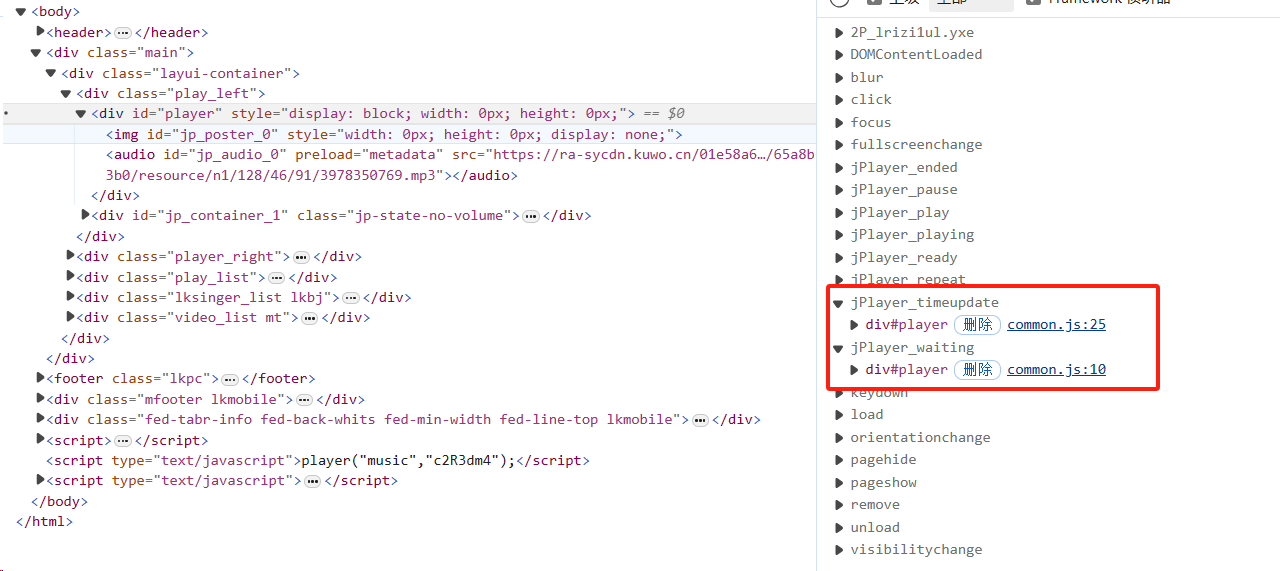
看到
jPlayer_waiting十分可疑,在第十行,进去打个断点,刷新,经过检验,audio及播放器就是在这里生成的,采用的是Ajax(异步加载技术)不过这没关系。因为我看见它上面写明了通过post提交方式获取到歌曲信息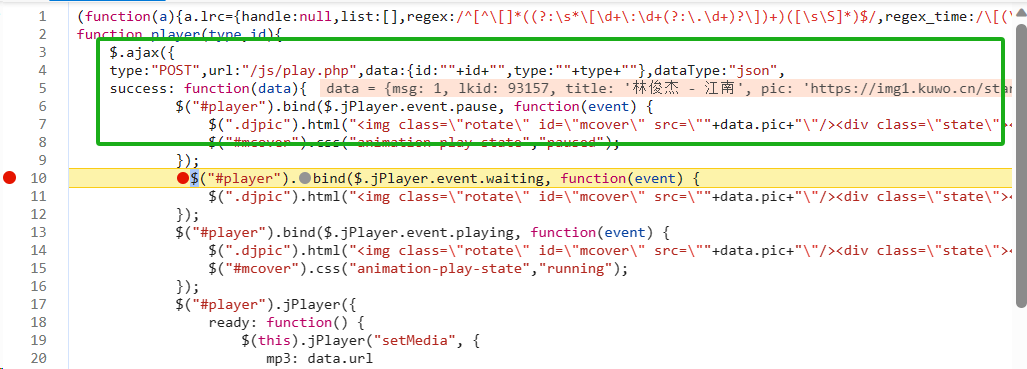
post请求,且数据只有id和type,应该是歌曲id和类型了,试一下这两个

去提交一下果然成功获取到了歌曲文件直链。
接下来就是完善一下代码:
1 | |
第五步、主程序创建
上面程序中,只能运行一次就结束运行了,创建个主程序,让它不在主动退出的情况下,能一直保持运行状态。
1 | |
后言

完整代码下载链接:点击进入下载