爬虫小练习-扒取网站小说
爬取网站小说并保存到本地の学习记录
前言
本次学习级别为新手村学习,简单易懂,特别适合刚学习python的练手项目。
- 请注意,本人提供的信息仅用于个人学习目的,并且不涉及公开或分享任何目标网站的相关链接或信息。爬取网站内容应遵守适用的法律法规、知识产权和隐私保护规定。在未获得授权的情况下,不得非法获取、使用或传播他人的数据、信息或资源。爬取操作应遵循合理的频率和并发量,以避免对目标网站造成过度负荷或干扰正常运营。本人不对任何因违反上述规定而导致的法律责任或纠纷承担责任。请确保你的行为符合相关法律法规,并尊重他人的权益和隐私。
爬虫的基本知识
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
需要安装的库
- requests
- bs4
- re
- time
一、构建获取小说的方法
打开网页,F12对小说页面内容进行分析。
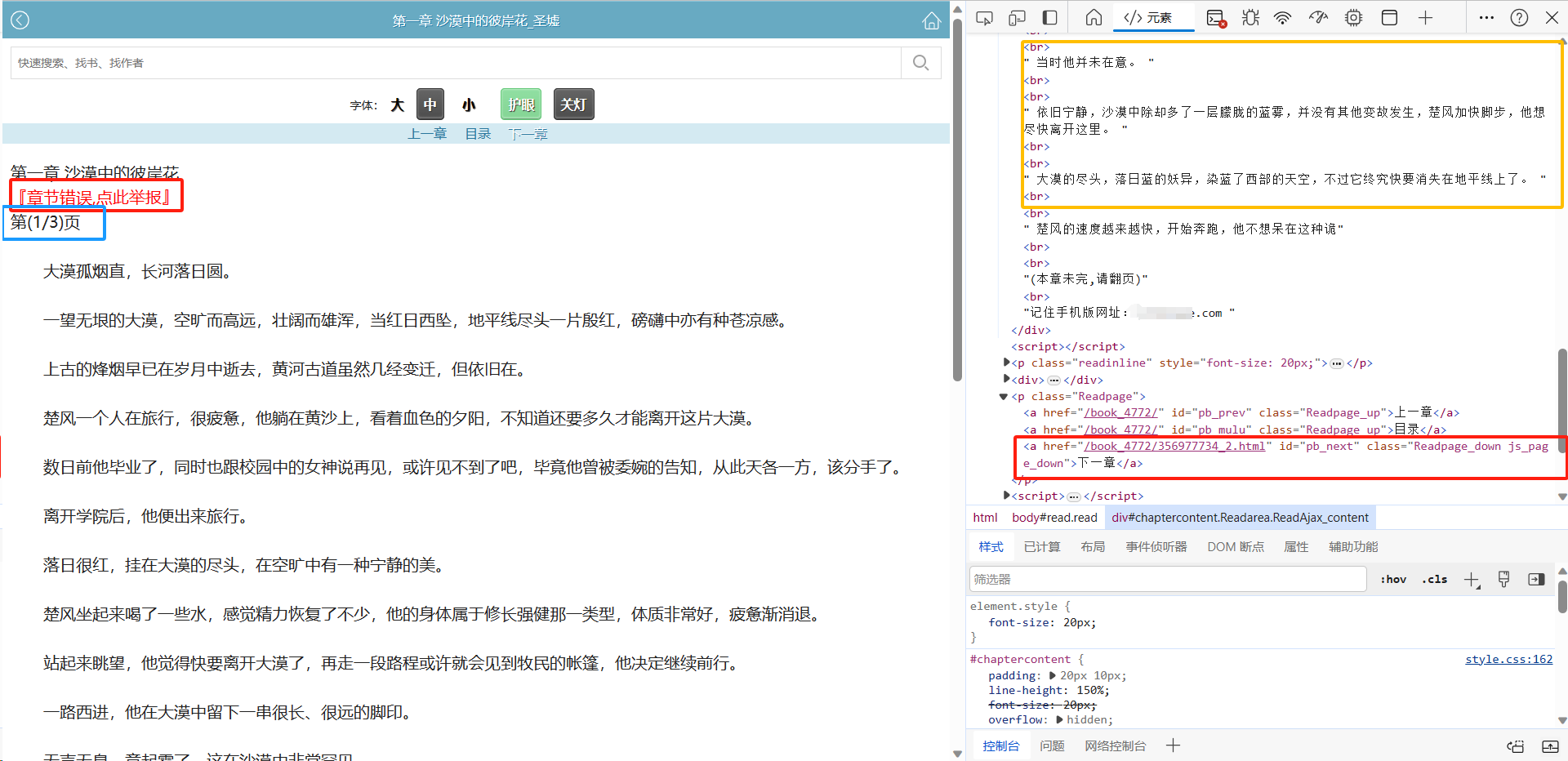
发现小说内容都在一个id为chaptercontent的div标签里面,并且用<br>标签分行保存,因此我们只需要获取<br>里面的内容就行了。但一章小说分了好多页,获取下一章按钮的href 值就能获取下一页的内容了。
代码如下
1 | |
二、对目录页进行解析
爬虫第一步,首先要明确直接要获取什么内容、理清整体思路。
- 解析网站
打开小说网站,随便打开一部小说的目录页面。
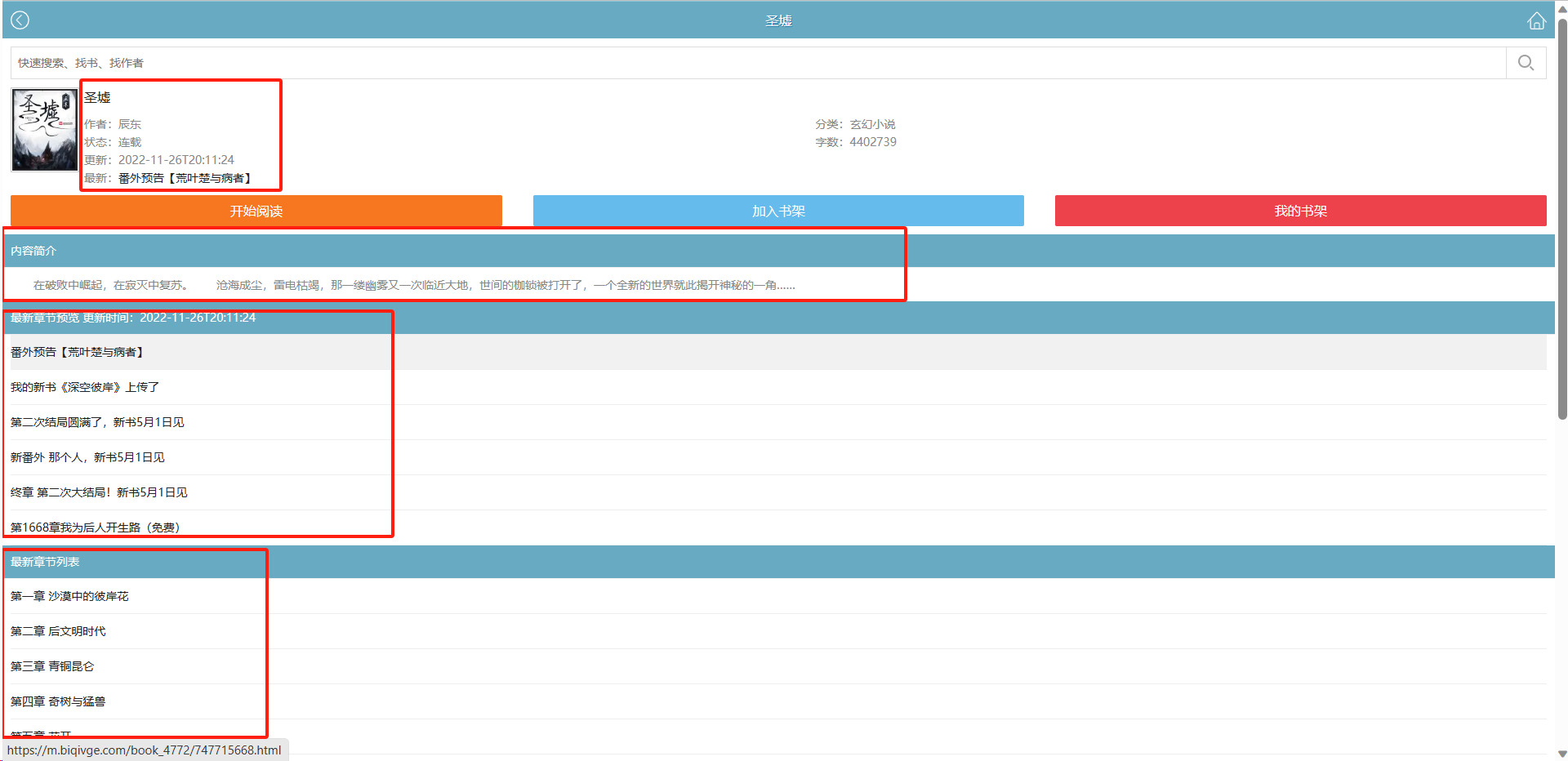
从表面上我们可以获取到信息有:小说名称、小说详细信息、内容简介、最新章节预览、最新章节列表。
获取小说名字
按F12,查看网页元素结构、对网页结果进行解析。
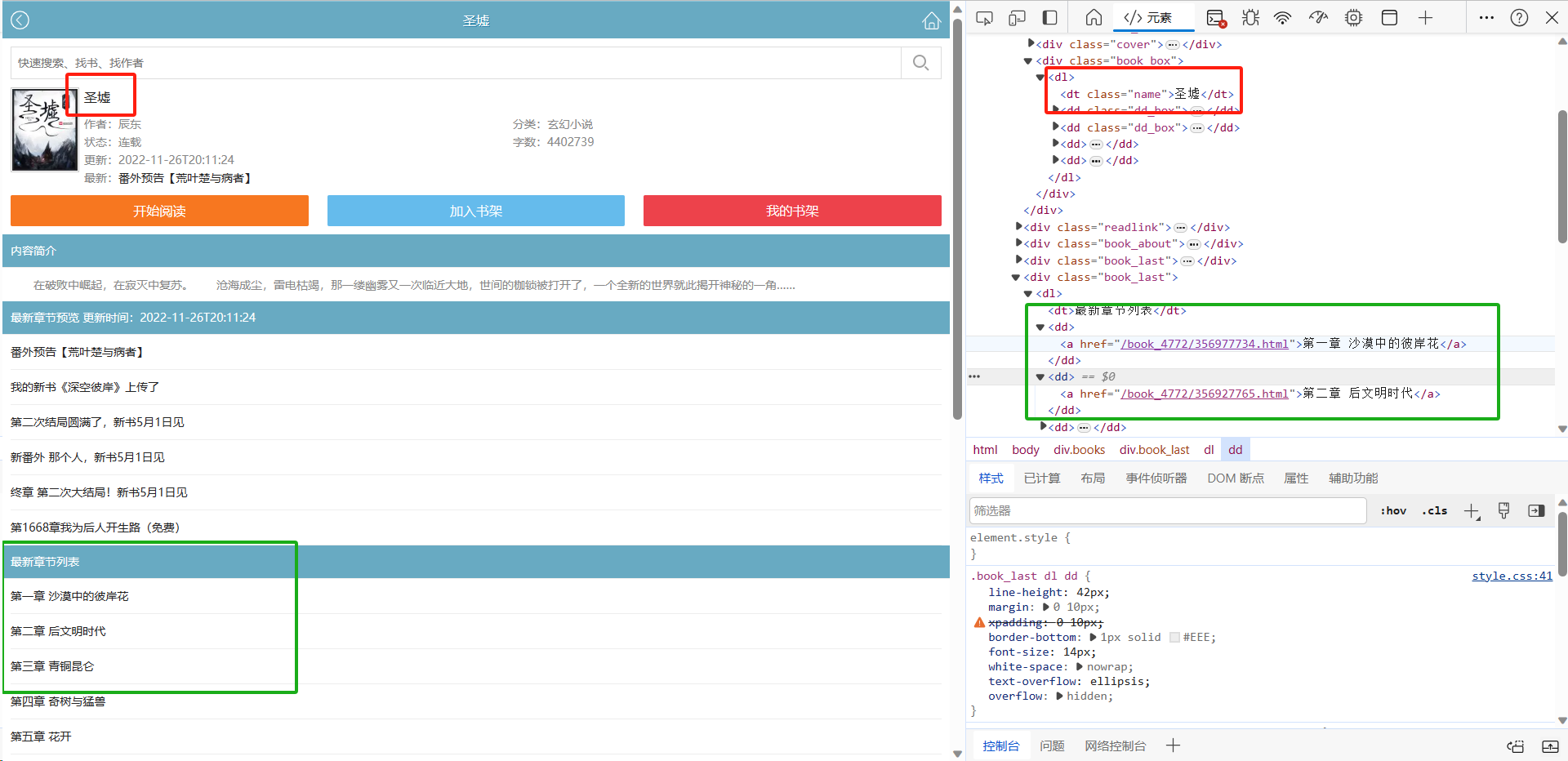
如图,不难找到存放小说名称的标签
dt、属性class,复制链接url、用python获取一下小说名称。1
2
3
4
5
6
7
8
9headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
name = soup.find('dt', class_='name').text.strip()
print(f'小说名称:{name}')还可以获取其他信息,方法一样,只需要修改标签和class的值就行
获取章节的链接
如图,章节链接都存放在属性为
book_last的div标签里,但是这里有两个同样的标签,需要获取第二个。
获取章节名称
如上图,章节名称存放在标签
<a> <a/>之间,在获取章节链接的同时可以同时获取章节名称获取目录页链接
查看整个页面,一个页面只显示前面前二十章,也就是说这一页只有前面二十章的目录信息。点击下页看看。发现链接改变了


方法一:把2改成3跳转到了该小说的第三页 ,一次类推下去就是整部小说的章节目录了(但是这种方法有局限性)
方法二:获取下一页按钮的
href值调用get_text方法实现下载小说
代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63import time
import requests
from bs4 import BeautifulSoup
import get_text
url = 'https://.com/book_19922/'
# 获取域名
index = url.find('/b')
zhangjie_url = url[url.find('/b'):]
if index != -1:
web = url[:index]
else:
print("未找到 'ch'")
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
# 发送请求获取小说首页内容
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取小说名称
name = soup.find('dt', class_='name').text.strip()
print(f'小说名称:{name}')
while True:
# 拼接章节url
url_line = web + zhangjie_url
# 发送请求获取章节内容页
response_1 = requests.get(url_line, headers=headers)
html_1 = response_1.text
soup_1 = BeautifulSoup(html_1, 'html.parser')
zhangjie_url = soup_1.find('a', class_="onclick").get('href')
# 使用选择器定位符合条件的元素
element = soup_1.select_one('.book_last dl dt:-soup-contains("最新章节列表")')
link = None
text = None
# 遍历获取标签里面的内容
if element:
parent_element = element.parent # 获取父级元素 dl
for tag in parent_element.find_all('dd'):
if tag.name == 'dd' and tag.a:
link = tag.a.get('href') # 获取 href 属性的值
text = tag.a.text.strip() # 获取文本内容
text_url = web + link
# 传递小说页过去
downld = get_text.get_text(text_url, name, text)
if downld:
time.sleep(0.5)
else:
print(f"{text}下载失败,请检查")
if link is None and text is None:
print(f"小说《{name}》,下载完成!")
break
time.sleep(3)三、整体逻辑
在已经获得小说目录链接[1]的前提下,创建一个循环:获取小说名字,获取目录页的章节链接,获取章节名字。然后把章节链接,小说名字,章节名字传递到获取的小说方法
get_text里去下载章节内容,下载成功则继续下一遍循环,错误则结束运行。